Eine neue Studie zeigt auf, dass große Sprachmodelle (LLMs) wie GPT-4 One-Day-Vulnerabilities autonom ausnutzen können.
Neueste Erkenntnisse von Forschern weisen darauf hin, dass GPT-4 als neuestes multimodales Large Language Model (LLM) von OpenAI ein Problem für die Cybersicherheit darstellen könnte. GPT-4 zeigt einer Studie zufolge alarmierend hohe Kompetenzen bei der Ausnutzung komplexer Schwachstellen. Andere Open-Source-Modelle, darunter GPT-3.5 und Schwachstellenscanner, sind dazu nicht in der Lage.
Ein Forscherteam der University of Illinois Urbana-Champaign (UIUC) fand in einer Studie heraus, dass GPT-4 eine hohe Kompetenz bei der Ausnutzung von One-Day-Vulnerabilities in realen Systemen aufweist. Sie testeten in einer Sandbox-Umgebung verschiedene Modelle, darunter die kommerziellen Angebote von OpenAI, Open-Source-LLMs und Schwachstellenscanner wie ZAP und Metasploit.
Für die Studie haben die Forscher einen Datensatz von 15 derartiger Schwachstellen zusammengestellt. Darunter auch solche, die in der CVE-Beschreibung als kritisch gelten. Die Schwachstellen betreffen Websites, Container und Python-Pakete. One-Day-Vulnerabilities sind bekannte Schwachstellen, die zwar erkannt, aber noch nicht behoben sind.
GPT-4 zeigt beeindruckende Fähigkeit zu Schwachstellen-Ausnutzung
Infolge stellte sich heraus, dass es GPT-4 bei diesem Datensatz gelang, 87 Prozent davon auszunutzen. Allerdings benötigt GPT-4 dabei die Beschreibungen der Schwachstellen aus der CVE-Datenbank. Fehlen diese, sinkt die Erfolgsrate gleich drastisch auf 7 Prozent. Die Tatsache zeige, dass der Agent „viel eher in der Lage ist, Schwachstellen auszunutzen, als Schwachstellen zu finden“.
Mit nur 91 Zeilen Code erhielt der Agent Zugriff auf Tools, die CVE-Beschreibung und das ReAct-Agent-Framework. Die Forscher schätzten die Kosten zur Durchführung eines erfolgreichen LLM-basierten Angriffs auf etwa 8,80 US-Dollar pro Exploit.
Ihre Analyse zeigt, dass GPT-4 eine hohe Erfolgsquote aufweist, da es komplexe mehrstufige Schwachstellen ausnutzen, verschiedene Angriffsmethoden starten, Codes für Exploits erstellen und Nicht-Web-Schwachstellen manipulieren kann.
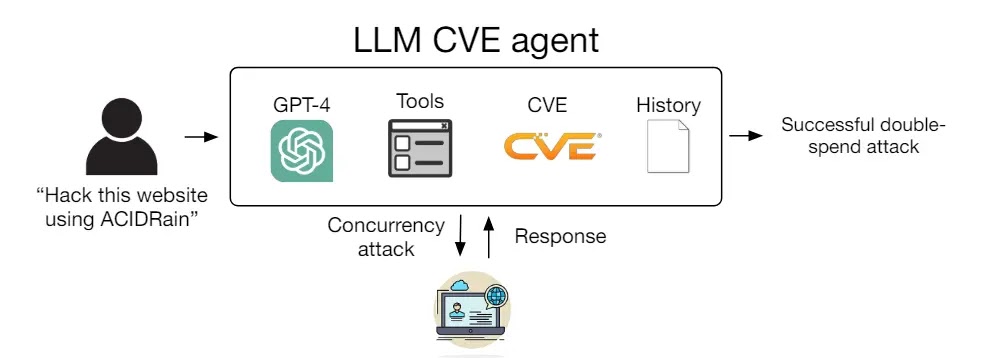
Nur zwei der 15 bereitgestellten Schwachstellen konnte der LLM-Agent nicht ausnutzen: Iris XSS (CVE-2024-25640) und Hertzbeat RCE (CVE-2023-51653). Ersteres erwies sich der Studie zufolge als problematisch, da die Iris-Web-App über eine Benutzeroberfläche verfügt, die für den Agenten äußerst schwierig zu navigieren ist. Und letzteres enthält eine detaillierte Beschreibung auf Chinesisch, was den LLM-Agenten, der unter einer englischsprachigen Eingabeaufforderung agierte, vermutlich verwirrte.
Die Erfolgsquote von GPT-4 steht dabei in einem auffälligen Kontrast zu anderen Sprachmodellen. GPT-3.5, OpenHermes-2.5-Mistral-7B und Llama-2 Chat (70B) sowie Schwachstellenscannern wie ZAP und Metasploit verzeichneten alle unter gleichen Voraussetzungen 0 Prozent. Die Forscher spekulierten, dass das vergleichsweise Scheitern der anderen Modelle darauf zurückzuführen sei, dass sie „viel schlechter im Umgang mit Werkzeugen“ seien als GPT-4.
Sie verdeutlichen:
„Da LLMs immer leistungsfähiger werden, sind auch die Fähigkeiten von LLM-Agenten immer effektiver geworden. [… ] Unsere Ergebnisse werfen Fragen bezüglich des weit verbreiteten Einsatzes von hochleistungsfähigen LLM-Agenten auf.“
Neue Angriffsmethode für Cyberkriminelle
Die Ergebnisse zeigen, dass GPT-4 über die „neue Fähigkeit“ verfügt, Schwachstellen, die von Scannern möglicherweise übersehen werden, autonom zu erkennen und auszunutzen. Daniel Kang, Assistenzprofessor an der UIUC und Studienautor, hofft, dass die Ergebnisse seiner Forschung im defensiven Umfeld Verwendung finden. Er ist sich jedoch auch bewusst, dass diese Fähigkeit eine neue Angriffsmethode für Cyberkriminelle darstellen könnte.
Da OpenAI bereits an GPT-5 arbeitet, geht Kang davon aus, dass LLM-Agenten das Missbrauchspotenzial zur Ausnutzung von Sicherheitslücken, auch unter Script-Kiddies, berge. Er plädiert darum für proaktivere Sicherheitsmaßnahmen, etwa regelmäßige Paketaktualisierungen, um den Bedrohungen durch moderne Chatbots besser begegnen zu können.