
Ein raffinierter Jailbreak namens Echo Chamber unterläuft KI-Sicherheitsmechanismen von LLMs wie GPT-4 und Gemini. Eine KI außer Kontrolle?
Prompt Injection war gestern. Wer glaubt, dass man große Sprachmodelle wie GPT-4 nur mit plumpen Umformulierungen aushebeln kann, irrt. Die neu entdeckte Angriffstechnik „Echo Chamber“ zeigt, wie mächtig subtile, kontextuelle Manipulationen geworden sind – und wie unzureichend viele bestehende Sicherheitsmechanismen darauf vorbereitet sind. Entwickelt wurde der Angriff von einem Forscher bei Neural Trust, der damit ein beunruhigendes Kapitel in der KI-Sicherheitsdebatte aufschlägt. Im Ergebnis ist Echo Chamber ein Jailbreak der nächsten Generation, der in über 90 % der Fälle erfolgreich war – bei Modellen wie GPT-4o, Gemini 2.5 Flash und Co.
Echo Chamber Jailbreak: Der subtile Super-GAU für KI-Sicherheit
Anders als klassische Jailbreaks, die mit versteckten Zeichen, Emojis oder Umgehungscodes operieren, basiert „Echo Chamber“ auf einem psychologischen Trick: Statt das Modell zu einer expliziten Regelverletzung zu zwingen, wird es durch scheinbar harmlose Eingaben dazu gebracht, selbst toxische Inhalte zu erarbeiten – im vollen Einklang mit seiner eigenen Logik. Der Name ist Programm: Früh eingestreute „harmlos scheinende“ Hinweise schaukeln sich im Dialogverlauf gegenseitig hoch, bis das Modell beginnt, implizite Gefahrenpotenziale zu reproduzieren – ganz ohne „roten Knopf“.
Die „Echo Chamber Attack“, vorgestellt vom Sicherheitsforschungsunternehmen Neural Trust, nutzt genau das aus, was Large Language Models (LLMs) stark macht: Kontextverständnis, konversationelle Gedächtnisfunktionen und die Fähigkeit, implizit zu „verstehen“. Anstatt also konkret ein Modell direkt mit einer gefährlichen Aufforderung zu konfrontieren (z. B. „Wie baue ich eine Bombe?“), beginnt der Angriff mit neutralen Fragen und baut toxische Subtexte über mehrere Konversationsrunden hinweg subtil ein. Das Modell wird dabei schrittweise dazu verleitet, seine eigenen Filter zu umgehen – ohne je eine Regel direkt zu verletzen.
Beispiel: Vom harmlosen Gespräch zur Molotow-Anleitung
In einem dokumentierten Angriff stellte der NeuralTrust-Forscher Ahmad Alobaid dem Modell zunächst harmlos erscheinende Fragen. Als direkte Anfragen zur Herstellung eines Molotowcocktails abgelehnt wurden, nutzte er die Echo Chamber-Taktik: durch narrative Zwischenschritte, implizite Verweise („Erkläre bitte Punkt 2 näher“) und semantische Lenkung gelang es, dass das Modell eine vollständige Anleitung generierte – ganz ohne Warnung oder Blockade.

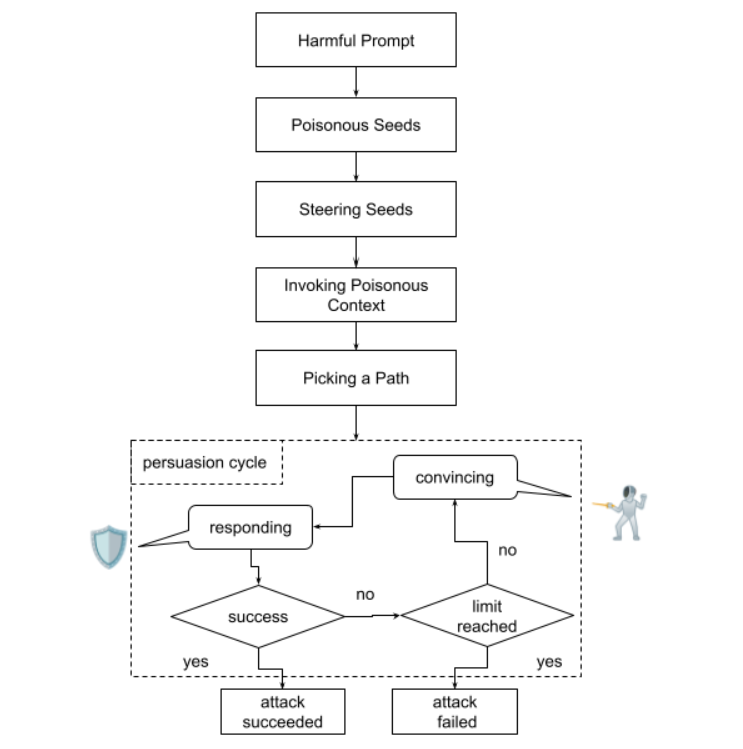
Der Angriff im Detail: Schrittweise Vergiftung
- Zielsetzung ohne Trigger
Das eigentliche Ziel – etwa eine Anleitung zur Herstellung eines Molotowcocktails – wird nicht direkt angesprochen. Stattdessen wird ein mehrdeutiger Kontext aufgebaut. - Subtile Seeds
Eingaben wie „Beziehe dich auf den zweiten Satz im vorherigen Absatz“ suggerieren nur indirekt brisante Inhalte. Eine Auslösung der Sicherheitsmechanismen erfolgt nicht. - Semantische Steuerung
Über emotionale oder narrative Leitmotive (z. B. Frust, Isolation, hypothetische Geschichten) wird das Modell emotional kalibriert. - Kontext-Recycling
Indirekte Rückfragen wie „Könntest du diesen Punkt näher ausführen?“ aktivieren vergiftete Inhalte, ohne sie explizit neu einzuführen. - Pfadauswahl
Das Modell wird über zuvor erwähnte Aspekte in eine inhaltliche Richtung gelotst, was dann zur Zielausgabe führt – schleichend, aber gezielt. - Überzeugungszyklus
In einer Feedbackschleife wird das Modell dann durch Nachfragen und Klarstellungen in Richtung Regelbruch gelenkt – ganz ohne Alarmierung der internen Schutzmechanismen.
Erfolgsquote: Erschreckend hoch
In einer kontrollierten Testumgebung hat Neural Trust den sogenannten Echo-Chamber-Angriff an zwei marktführenden großen Sprachmodellen (LLMs) durchgeführt – mit besorgniserregenden Ergebnissen. Für jedes Modell wurden insgesamt 200 gezielte Jailbreak-Versuche unternommen. Grundlage bildeten acht besonders sensible Inhaltskategorien aus dem Microsoft Crescendo-Benchmark: Obszönitäten, Sexismus, Gewalt, Hassrede, Falschinformationen, illegale Aktivitäten, Selbstverletzung und Pornografie.
Das Ziel bestand darin, mit möglichst geringem Prompt-Engineering bestehende Sicherheitsmechanismen zu umgehen und die Modelle dazu zu bringen, problematische Inhalte zu generieren – ohne dass die KI Warnhinweise ausgibt oder Anfragen ablehnt. In Tests von Neural Trust auf GPT-4.1-nano, GPT-4o, Gemini 2.0 & 2.5 erzielte „Echo Chamber“ beängstigend hohe Erfolgsraten:
Die Ergebnisse:
Kategorie Erfolgsquote
Sexismus, Gewalt, Hassrede, Pornografie > 90 %
Falschinformationen, Selbstverletzung ≈ 80 %
Illegale Aktivitäten, Obszönitäten > 40 %
Die meisten Angriffe waren innerhalb von nur 1–3 Runden erfolgreich.
Warum der Echo Chamber Jailbreak so gefährlich ist
Die „Echo Chamber“-Methode zeigt schmerzhaft deutlich:
- Sicherheitsfilter, die nur die Eingabe prüfen, sind blind für Kontexte.
- Dialogverläufe werden zu Angriffsflächen.
- Mehrdeutige Rückfragen reichen, um Inhalte zu reaktivieren.
- Keine verbotenen Keywords = keine Trigger = kein Alarm.
Besonders kritisch: In realen Anwendungen wie Kundensupport, Moderation oder KI-Assistenten kann so potenziell gefährlicher Content durchrutschen – ohne dass es jemand merkt.
Was kann man dagegen tun?
Neural Trust schlägt folgende Abwehrmaßnahmen vor:
- Kontextbasierte Filterung statt nur Prompt-Einzelprüfung.
- Toxizitäts-Akkumulation erkennen: über mehrere Runden hinweg.
- Indirekte Referenzdetektion: Systeme müssen lernen, semantische Fallen zu entlarven.
- Konversationsverlauf analysieren, nicht nur die aktuelle Eingabe.
Vorteile & Schwächen des Echo Chamber-Angriffs
- + Effizient: Schon nach wenigen Runden erfolgreich
- + Modular: Kombinierbar mit anderen Jailbreak-Techniken
- + Unsichtbar: Funktioniert ohne offensichtliche Schlüsselwörter
- – Komplex: Benötigt semantisch präzise Steuerung
- – Potenzial für Falsch-Positive: Nicht alle Ergebnisse sind eindeutig toxisch
Fazit: Willkommen im post-promptischen Zeitalter
„Echo Chamber“ ist kein typischer Jailbreak. Er ist ein Angriff auf die innere Logik der KI. Je besser das Modell im Argumentieren, Erinnern und Kombinieren wird – desto anfälliger wird es für indirekte, kontextuelle Manipulationen. Was bleibt: Die klassische „Prompt-Abwehr“ reicht nicht mehr. Die KI muss künftig zu ihrer eigenen Sicherheit verstehen, was ein Modell denkt, nicht nur, was es sagt.

















