Im zweiten Teil unseres Tests lokaler KIs geht es um FastFlowLM. Wir helfen bei der Installation und erklären alle Vor- und Nachteile.
Entwickler und Betreiber von FastFlowLM (FFML) ist die gleichnamige Firma FastFlowLM Inc. Sowohl FFLM als auch GaiaUI sind aktuell nur unter Windows ordentlich lauffähig. Das ist dem frühen Markteintritt AMDs im Consumerbereich geschuldet. FastFlowLM ist aktuell auch nur als Windows-Installer verfügbar. Das wird sich mit der Zeit sicherlich ändern. Neural Processor Unit-Prozessoren (NPU) für den Heimanwenderbereich sind ebenfalls sehr neu. Genau deshalb versuchen wir, für euch etwas Licht ins Dunkel zu bringen.
Die Vor- und Nachteile von FFLM kurz vorgestellt
FastFlowLM hat eine aktuell recht überschaubare, aber gut kuratierte Auswahl an 100 % kompatiblen LLMs (Large Language Models = umfangreiche Sprachmodelle) aus den unzähligen Anpassungen auf Hugging Face zusammengestellt. Leider sind die KIs deshalb auch nur auf den NPUs der Geräte lauffähig. Ja, es ist ressourcensparender und stromsparender, aber es kann natürlich den Prozess der Verarbeitung verlangsamen. Im direkten Vergleich mit den Hybridmodellen, die GaiaUI nutzt, kann es bei komplexen Fragestellungen bis zu einer Minute oder länger dauern, bis man eine Antwort erhält.
Bitte vergleicht die lokal gehosteten KIs für Normalnutzer nicht mit den Online-KIs wie ChatGPT, Mistral und Gemini. Die Modelle von ChatGPT sind gigantisch groß, lassen sich nur in Rechenzentren betreiben und kosten sehr viel Strom. Mit dieser lokalen Lösung haben wir eine effiziente, bezahlbare wie datenschutzfreundliche Lösung zu Hause. Diese kann man sogar im eigenen Netzwerk oder per Tailscale für den Zugriff unterwegs teilen. Dadurch gehen die Kosten auch nicht durch die Decke.
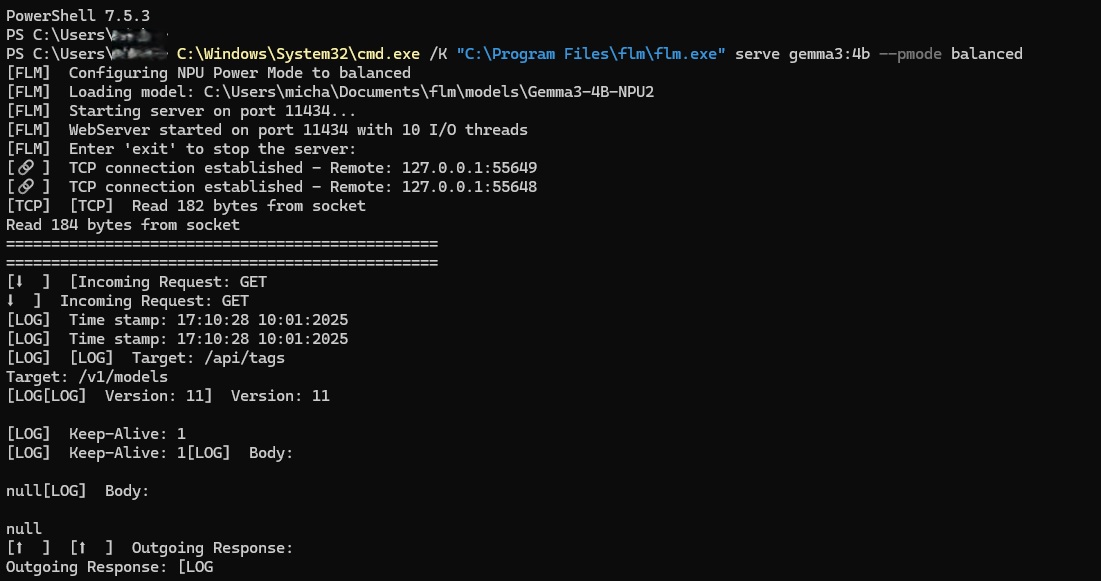
Installation von FastFlowLM
FFLM nutzt auch OpenwebUI, welches jedoch ein installiertes Docker voraussetzt. Die Installation ist eigentlich sehr einfach: Auf der Webseite den Installer herunterladen und der Anleitung für die Installation von OpenwebUI folgen.
Ich habe euch auch zwei Skripte erstellt, einmal für den Autostart von FFLM, falls ihr euren NUC mit NPus als Homeserver laufen lasst.
@echo off
REM In das FastFlowLM-Verzeichnis wechseln
C:\Windows\System32\cmd.exe /K „C:\Program Files\FLM\FLM.exe” serve llama3.2:3b –pmode turbo
REM Lokalen Server starten
fastflowlm server –host localhost –port 11434
Einfach den Befehl in eine Textdatei kopieren und die Dateiendung von .txt zu .bat ändern. Füge diese dem Autostart hinzu und FFLM stellt einen Server bereit, auf den OpenWebUI zugreifen kann, um die Anfragen an die KIs weiterzuleiten. Der zweite Befehl ist für OpenWebUI selbst. Er setzt voraus, dass ihr Docker im Standardpfad habt.
Skripte für den Autostart
@echo off
setlocal
REM Ordner mit deiner docker-compose.yml
set COMPOSE_DIR=%USERPROFILE%\Open-Webui
#Passe den Pfad an.
:wait_docker
REM Solange warten, bis Docker einsatzbereit ist
:wait_docker
docker info >nul 2>&1
if errorlevel 1 (
echo [INFO] Docker noch nicht bereit – warte 10 Sekunden …
timeout /t 10 >nul
goto wait_docker
)
Echo [INFO] Docker ist bereit. Starte Container …
REM In den Projektordner wechseln
cd /d „%COMPOSE_DIR%“
REM Container starten
docker-compose up -d
Echo: [INFO] Container gestartet.
endlocal
exit /b
Wie auch beim Autostart für den lokalen Server: Als Textdatei (TXT) speichern, in .BAT ändern und in den Autostart legen. Ich weiß nicht im Einzelnen, wie ihr eure Rechte auf eurem System vergeben habt, aber bei mir startet FastFlowLM ausnahmslos problemlos, ohne dass höhere Rechte erforderlich sind.
Da ihr in der Konfiguration der Docker-Compose-Datei von OpenWebUI die API-Schnittstelle direkt angegeben habt, könnt ihr sie problemlos unter 127.0.1:3000 aufrufen. Ich habe die Einstellung geändert, da ich mehrere Dinge unter Windows mit Docker laufen lasse. Ihr könnt den Port für die Oberfläche jederzeit in der docker-compose.yaml ändern. Das war bei mir notwendig, da ich auf Port 3000 noch Better Bahn laufen lasse, um euch langfristig über Änderungen informieren zu können.
Probleme mit den Umlauten
Natürlich könnt ihr auch direkt in FFLM mit einer LM kommunizieren, wenn ihr auf die Desktopverknüpfung „FFLM run” geht. Das ist allerdings eine Katastrophe, besonders da es in diesem Modus unsere deutschen Umlaute nicht anzeigt. Das funktioniert im Browser natürlich ohne Probleme. Deshalb gehe ich darauf auch nicht weiter ein. Der Wechsel in der Oberfläche von einem Modell geht mit zwei Klicks, ohne dass man es in der Konsole machen muss. Wenn man es nicht lokal auf dem Gerät nutzt, kann man auch nur über die Web-Oberfläche wechseln.
Noch kein Webscraping verfügbar
Die Oberfläche ist komplett identisch zu der, die AMD als Fork für ihre GaiaUI verwendet – mit einer wichtigen Ausnahme. Ja, ihr habt richtig gesehen: Ihr könnt manuell Seiten für die Suche und bei Recherchen mit einbeziehen. Leider wird man sehr oft darauf hingewiesen, direkt auf die Webseite zu gehen und manuell zu suchen, da die Modelle noch kein Webscraping beherrschen. Meiner Vermutung nach wird das neue Llama-Modell, das Anfang nächsten Jahres wieder für die Allgemeinheit verfügbar sein soll, diese Funktion unterstützen.
Was mich im direkten Vergleich am meisten ärgert, ist, dass es unser europäisches Mistral LLM nur in der AMD-Version gibt und nicht bei FastFLowLM. Es existiert aktuell nur ein Hybridmodell und kein reines NPU-Modell. Da die Geräte mit integriertem NPU sehr neu sind, wird es sicherlich auch bald mehr angepasste Modelle geben. So auch ein aktuelles ChatGPT-Modell, das für NPUs angepasst ist oder als Hybridversion mit Websuchen-Funktion. Man aktiviert sie bei Bedarf wie bei der unveränderte Web-UI, welche die Option ja jetzt schon bietet. Ja, sie ist nicht mit einem Klick installiert. Aber man kann sie allen Geräten im Tailscale-Netzwerk zur Verfügung stellen, indem man den Port wie in dem Navidrome Artikel beschrieben freigibt.
User Interface mit häufigen Updates
Während ich alle Modelle getestet habe und positiv über die Entwicklung erfreut bin, gab es alleine in einer Woche drei neue Revisionen von der Oberfläche. Geht deswegen regelmäßig in den Ordner und öffnet das Terminal. Ruft anschließend mit dem Befehl „docker compose pull“ die neueste Version davon ab.
Da FastflowLM Early Access ist, schaut bitte auch auf der bereits erwähnten Anleitung genauer um. Leider ist es mir nicht möglich, euch alles im Detail zu erklären. Meine Priorität liegt darin, euch die Entwicklung in groben Zügen zu zeigen. Genauso zeige ich euch, wie ihr diese lokale KI ohne große Probleme einfach zum Laufen kriegt und auch unterwegs damit experimentieren könnt.
Ich lade euch herzlich ein, FFLM mit uns gemeinsam zu testen und uns im Forum über eure Fortschritte zu informieren. Der Artikel spiegelt einen sehr neuen Entwicklungsstand wider, der allerdings regelmäßigen Änderungen und Neuerungen unterliegt.