
Anwender der Adobe Creative Cloud stellen ihre Werke automatisch für das Training von KI-Algorithmen bereit - bis sie aktiv widersprechen.
Wer dem nicht aktiv in den Datenschutzeinstellungen seines Accounts widerspricht, stellt seine in der Adobe Creative Cloud gespeicherten Werke automatisch für das Training von KI-Algorithmen bereit. Doch nicht jeder Nutzer dürfte von dieser Praxis begeistert sein. Der Softwarekonzern zeigt sich vorerst uneinsichtig.
Daten aus der Adobe Creative Cloud dienen automatisch dem KI-Training
In den vergangenen Monaten nahm das Thema „Künstliche Intelligenz“ (KI) zunehmend an Fahrt auf. Dabei geriet auch immer wieder die Urheberrechtsfrage in den Fokus, da Entwickler ihre KI-Algorithmen üblicherweise mit einer riesigen Datenmenge trainieren. So manch ein Anwender möchte aber gar nicht, dass man seine Werke dafür missbraucht.
Der Softwarehersteller Adobe macht es sich diesbezüglich ganz einfach, indem er ungefragt sämtliche Daten, die Benutzer in den Creative Cloud-Diensten gespeichert haben, für das Training seiner Algorithmen verwendet. Darauf deutete kürzlich die Krita Foundation via Twitter hin – eine Non-Profit-Organisation, die Open-Source-Grafiksoftware entwickelt und Teil der KDE-Community ist.
Analyse erfolgt in der Cloud, nicht aber auf lokalen Geräten
Auch im deutschen FAQ-Bereich des Unternehmens finden sich entsprechende Passagen. „Adobe analysiert unter Umständen Ihre Creative Cloud- oder Document Cloud-Inhalte, um Produktfunktionen zur Verfügung zu stellen und unsere Produkte und Dienste zu verbessern und weiterzuentwickeln„, heißt es dort.
Weiterhin erklärt Adobe, es verwende „hauptsächlich maschinelles Lernen in Creative Cloud und Document Cloud„, um die Daten der Anwender zu analysieren. Davon ausgeschlossen seien jedoch „Inhalte, die lokal auf Ihrem Gerät verarbeitet oder gespeichert werden.„
Die Frage, wie diese Inhaltsanalyse abläuft, beantwortet das Unternehmen wie folgt:
„Wenn wir Ihre Inhalte zur Verbesserung unserer Produkte und zu Entwicklungszwecken analysieren, aggregieren wir Ihre Inhalte zunächst mit anderen Inhalten und verwenden dann die aggregierten Inhalte, um unsere Algorithmen zu trainieren und somit unsere Produkte und Dienste zu verbessern.“
Adobe FAQ
In der Vergangenheit zeigten sich bereits viele Künstler frustriert über eine solche Praxis. Ihre Werke für das Training einer KI zu verwenden führt schließlich dazu, dass beliebte Tools wie Stable Diffusion oder Midjourney Inhalte generieren, die zwar nicht die Kunstwerke selbst, dafür aber zumindest den Stil der Rechteinhaber einfach kopieren.
Widerspruch gegen die Verwendung der Adobe Creative Cloud-Daten möglich
Wer die Creative Cloud nutzt, muss der Verwendung seiner Werke für das KI-Training von Adobe jedoch aktiv widersprechen, um seine Arbeit zu schützen. Tut er dies nicht, so betrachtet der Softwarehersteller dies automatisch als Erlaubnis.
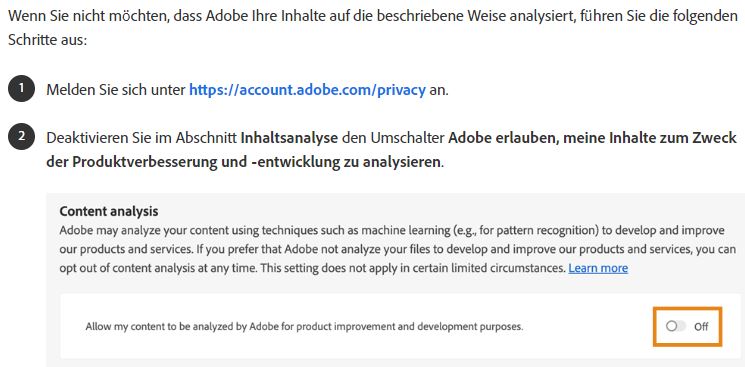
Gegenüber The Register verteidigte ein Unternehmenssprecher von Adobe die automatische Verwendung der Nutzerdaten:
„Wir geben unseren Kunden die volle Kontrolle über ihre Datenschutzpräferenzen und -einstellungen. Die zur Diskussion stehende Richtlinie ist nicht neu und wird seit zehn Jahren angewandt, um unsere Produkte für die Kunden zu verbessern. Für alle, die es vorziehen, dass ihre Inhalte von der Analyse ausgeschlossen werden, bieten wir diese Option hier an.“
Unternehmenssprecher von Adobe
Dennoch versicherte er, dass das Unternehmen seine Richtlinie derzeit überarbeite, „um die Anwendungsfälle für generative KI besser zu definieren.„
Im Gegensatz zu anderen Diensten hatte sich der Softwarekonzern erst im vergangenen Monat für den Einsatz und Verkauf von KI-generierten Bildern auf seiner Bild-Plattform Adobe Stock ausgesprochen.

















