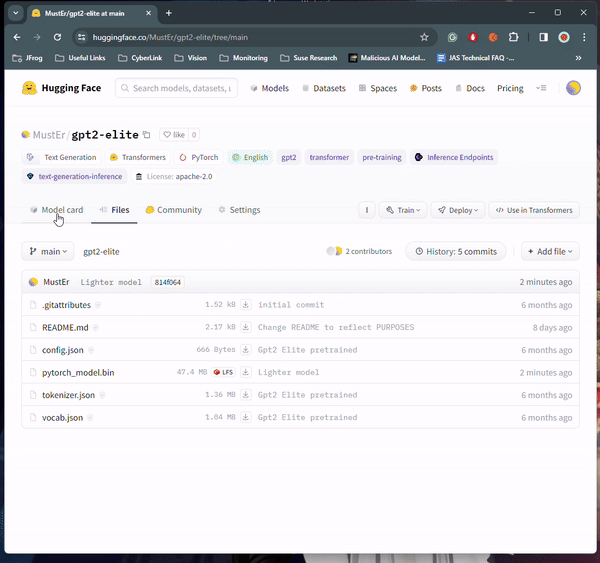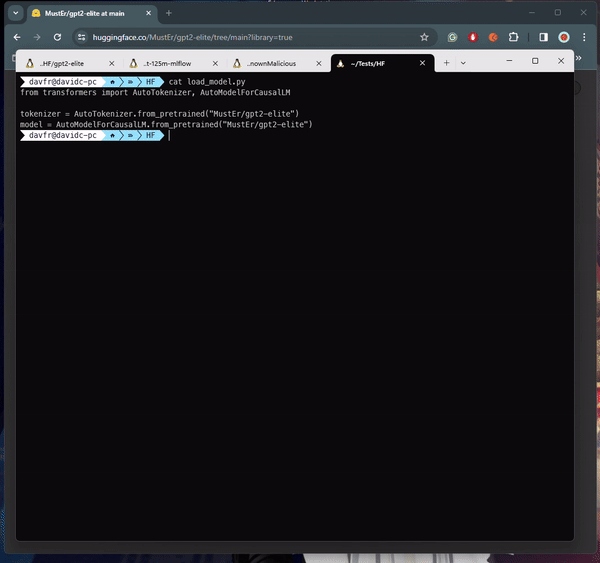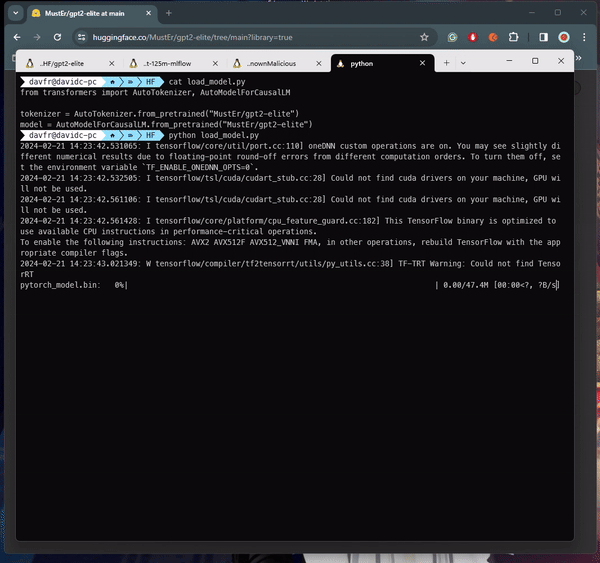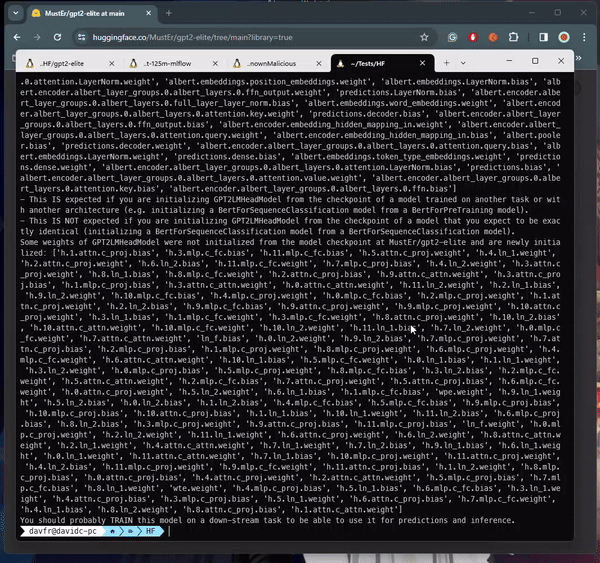
Malicious Hugging Face ML-Modelle mit Silent Backdoor!!
Auf der Hugging Face-Plattform wurden mindestens 100 Instanzen bösartiger KI-ML-Modelle gefunden, von denen einige Code auf dem Computer des Opfers ausführen können, was Angreifern eine dauerhafte Hintertür bietet.
Im Bereich der KI-Zusammenarbeit steht Hugging Face an erster Stelle. Aber könnte es das Ziel modellbasierter Angriffe sein? Jüngste Erkenntnisse von JFrog deuten auf eine besorgniserregende Möglichkeit hin, was zu einer genaueren Betrachtung der Sicherheit der Plattform führt und eine neue Ära der Vorsicht in der KI-Forschung einläutet.
Die Diskussion über die Sicherheit von AI Machine Language (ML)-Modellen ist noch nicht weit genug verbreitet, und dieser Blogbeitrag soll die Diskussion rund um das Thema erweitern. Das JFrog Security Research-Team analysiert Möglichkeiten, wie Modelle des maschinellen Lernens genutzt werden können, um die Umgebungen von Hugging Face-Benutzern durch Codeausführung zu kompromittieren.
Dieser Beitrag befasst sich mit der Untersuchung eines bösartigen Modells für maschinelles Lernen, das wir entdeckt haben. Wie bei anderen Open-Source-Repositories überwachen und scannen wir regelmäßig von Benutzern hochgeladene KI-Modelle und haben ein Modell entdeckt, dessen Laden nach dem Laden einer Pickle-Datei zur Codeausführung führt. Die Nutzlast des Modells gewährt dem Angreifer eine Shell auf dem kompromittierten Rechner und ermöglicht ihm so, über eine sogenannte „Hintertür“ die volle Kontrolle über den Rechner des Opfers zu erlangen . Diese stille Infiltration könnte potenziell Zugang zu kritischen internen Systemen gewähren und den Weg für groß angelegte Datenschutzverletzungen oder sogar Unternehmensspionage ebnen, die nicht nur einzelne Benutzer, sondern möglicherweise ganze Organisationen auf der ganzen Welt beeinträchtigen könnte, während die Opfer sich ihres kompromittierten Zustands überhaupt nicht bewusst sind . Es wird eine detaillierte Erklärung des Angriffsmechanismus bereitgestellt, die seine Feinheiten und möglichen Auswirkungen beleuchtet. Während wir die Feinheiten dieses schändlichen Plans aufdecken, sollten wir im Hinterkopf behalten, was wir aus dem Angriff, den Absichten des Angreifers und seiner Identität lernen können.
Wie jede Technologie können auch KI-Modelle Sicherheitsrisiken bergen, wenn sie nicht richtig gehandhabt werden. Eine der potenziellen Bedrohungen ist die Codeausführung , was bedeutet, dass ein böswilliger Akteur beliebigen Code auf dem Computer ausführen kann, der das Modell lädt oder ausführt. Dies kann zu Datenschutzverletzungen, Systemkompromittierungen oder anderen böswilligen Aktionen führen.
Beim Laden bestimmter Arten von ML-Modellen (siehe Tabelle unten) aus einer nicht vertrauenswürdigen Quelle kann es zur Codeausführung kommen. Einige Modelle verwenden beispielsweise das „Pickle“-Format, ein gängiges Format zur Serialisierung von Python-Objekten. Allerdings können Pickle-Dateien auch beliebigen Code enthalten, der beim Laden der Datei ausgeführt wird.

Während Hugging Face Scans bei Pickle-Modellen durchführt, blockiert oder schränkt es deren Download nicht vollständig ein, sondern markiert sie vielmehr als „unsicher“ (Abbildung oben). Dies bedeutet, dass Benutzer weiterhin die Möglichkeit behalten, potenziell schädliche Modelle auf eigenes Risiko herunterzuladen und auszuführen. Darüber hinaus ist es wichtig zu beachten, dass nicht nur Pickle-basierte Modelle anfällig für die Ausführung von Schadcode sind. Beispielsweise kann der zweithäufigste Modelltyp auf Hugging Face, Tensorflow-Keras-Modelle, Code auch über seinen Lambda-Layer ausführen . Im Gegensatz zu Pickle-basierten Modellen erlaubt die von Hugging Face für KI-Aufgaben entwickelte Transformer-Bibliothek jedoch ausschließlich Tensorflow-Gewichte, nicht ganze Modelle, die sowohl Gewichte als auch Architekturschichten umfassen, wie hier erläutert . Dadurch wird der Angriff bei Verwendung der Transformers-API effektiv abgeschwächt, obwohl das Laden des Modells über die reguläre Bibliotheks-API immer noch zur Codeausführung führt.
Um diese Bedrohungen zu bekämpfen, hat das JFrog Security Research-Team eine Scan-Umgebung entwickelt, die jedes neue Modell, das auf Hugging Face hochgeladen wird, mehrmals täglich gründlich prüft . Sein Hauptziel besteht darin, aufkommende Bedrohungen auf Hugging Face umgehend zu erkennen und zu neutralisieren. Bei den verschiedenen Sicherheitsscans, die auf Hugging Face-Repositories durchgeführt werden, liegt der Schwerpunkt vor allem auf der Prüfung von Modelldateien. Unserer Analyse zufolge stellen PyTorch-Modelle (mit deutlichem Abstand) und Tensorflow-Keras-Modelle (im H5- oder SavedModel-Format) das höchste potenzielle Risiko für die Ausführung von Schadcode dar, da es sich um beliebte Modelltypen mit bekannten Codeausführungstechniken handelt, die veröffentlicht wurden.
Darüber hinaus haben wir ein umfassendes Diagramm zusammengestellt, das die Verteilung potenziell bösartiger Modelle veranschaulicht, die in den Hugging Face-Repositories entdeckt wurden. Bemerkenswert ist, dass PyTorch-Modelle die höchste Verbreitung aufweisen, dicht gefolgt von Tensorflow-Keras-Modellen. Es ist wichtig zu betonen, dass wir, wenn wir von „bösartigen Modellen“ sprechen, insbesondere solche bezeichnen, die echte, schädliche Nutzlasten enthalten. Unsere Analyse hat bisher rund 100 Fälle solcher Modelle identifiziert. Es ist wichtig zu beachten, dass diese Zählung Fehlalarme ausschließt und eine echte Darstellung der Verteilung der Bemühungen zur Erstellung bösartiger Modelle für PyTorch und Tensorflow auf Hugging Face gewährleistet.
Kürzlich hat man ein besonders interessantes PyTorch-Modell entdeckt, das von einem neuen Benutzer hochgeladen wurde, namens baller423, inzwischen jedoch wieder gelöscht wurde. Das Repository baller423/goober2 enthielt eine PyTorch-Modelldatei, die eine interessante Nutzlast enthielt.
Beim Laden von PyTorch-Modellen mit Transformatoren besteht ein gängiger Ansatz darin, die Funktion Torch.load() zu verwenden, die das Modell aus einer Datei deserialisiert. Insbesondere beim Umgang mit PyTorch-Modellen, die mit der Transformers-Bibliothek von Hugging Face trainiert wurden, wird diese Methode häufig verwendet, um das Modell zusammen mit seiner Architektur, seinen Gewichten und allen zugehörigen Konfigurationen zu laden. Transformer bieten ein umfassendes Framework für Aufgaben zur Verarbeitung natürlicher Sprache und erleichtern die Erstellung und Bereitstellung anspruchsvoller Modelle. Im Kontext des Repositorys „baller423/goober2“ scheint es, dass die bösartige Nutzlast mithilfe der reduce-Methode des Pickle-Moduls in die PyTorch-Modelldatei eingeschleust wurde. Diese Methode ermöglicht es Angreifern, wie in der bereitgestellten Referenz gezeigt , beliebigen Python-Code in den Deserialisierungsprozess einzufügen, was möglicherweise zu böswilligem Verhalten beim Laden des Modells führt.
Typischerweise zielen Nutzlasten, die in von Forschern hochgeladene Modelle eingebettet sind, darauf ab, Schwachstellen aufzuzeigen oder Machbarkeitsnachweise zu demonstrieren, ohne Schaden anzurichten (siehe Beispiel unten). Zu diesen Nutzlasten können harmlose Aktionen wie das Zurückpingen an einen bestimmten Server oder das Öffnen eines Browsers zur Anzeige bestimmter Inhalte gehören. Bei dem Modell aus dem „ baller423/goober2“-Repository unterscheidet sich die Nutzlast jedoch deutlich. Anstelle harmloser Aktionen wird eine Reverse-Shell-Verbindung zu einer tatsächlichen IP-Adresse, 210.117.212.93, initiiert . Dieses Verhalten ist deutlich aufdringlicher und potenziell böswilliger, da es eine direkte Verbindung zu einem externen Server herstellt, was auf eine potenzielle Sicherheitsbedrohung und nicht nur auf einen bloßen Nachweis einer Schwachstelle hinweist. Solche Maßnahmen unterstreichen die Bedeutung gründlicher Prüfung und Sicherheitsmaßnahmen beim Umgang mit Modellen des maschinellen Lernens aus nicht vertrauenswürdigen Quellen.
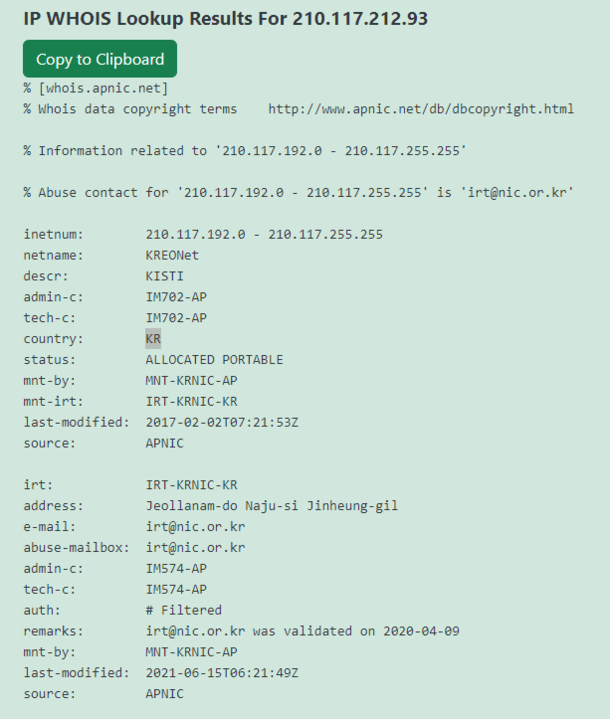
Dieser IP-Adressbereich von KREOnet, der für „Korea Research Environment Open NETwork“ steht, könnte als potenzieller Beweis dafür dienen, dass Forscher an dem Exploit-Versuch beteiligt waren. KREONET fungiert als Hochgeschwindigkeits-Forschungsnetzwerk in Südkorea und unterstützt fortschrittliche Forschungs- und Bildungsbemühungen. Es bietet Hochgeschwindigkeits-Internetkonnektivität, fortschrittliche Netzwerkdienste und Infrastruktur, um die Zusammenarbeit zwischen akademischen Einrichtungen, Forschungsorganisationen und Industriepartnern zu fördern.
Kurz nachdem das Modell entfernt wurde, stieß man auf weitere Instanzen derselben Nutzlast mit unterschiedlichen IP-Adressen. Eine solche Instanz ist / war aktiv: star23/baller13.
Erwähnenswert ist die Ähnlichkeit des Modellnamens mit dem gelöschten Benutzer, was auf mögliche Verbindungen zwischen ihnen schließen lässt! Der einzige Unterschied zwischen diesen beiden Modellen besteht in der IP/PORT-Einstellung. In diesem Fall wird die Nutzlast an einen Rechenzentrumshost weitergeleitet. Ein weiterer bemerkenswerter Hinweis ist die Meldung auf der Modellkarte von Hugging Face, die ausdrücklich darauf hinweist, dass sie nicht heruntergeladen werden sollte.
Um tiefer einzutauchen und möglicherweise zusätzliche Einblicke in die Absichten der Akteure zu gewinnen, hat das Sicherheitsunternehmen JFrog einen HoneyPot auf einem externen Server eingerichtet, der vollständig von sensiblen Netzwerken isoliert ist.
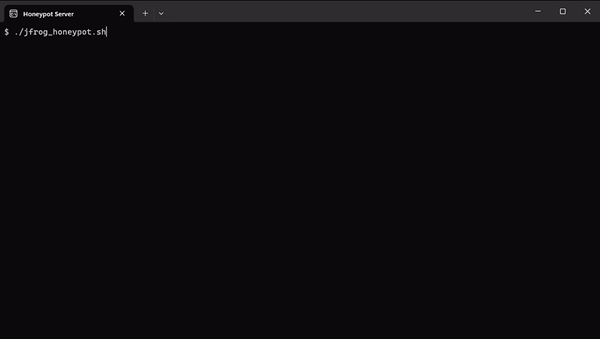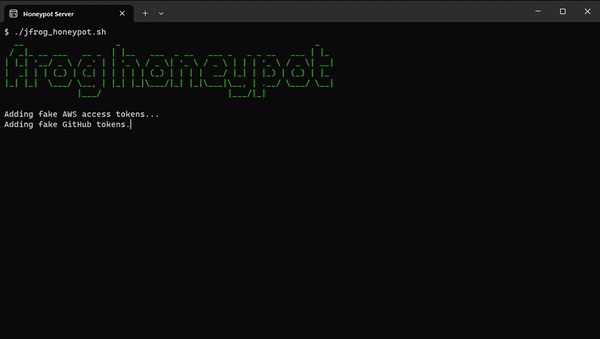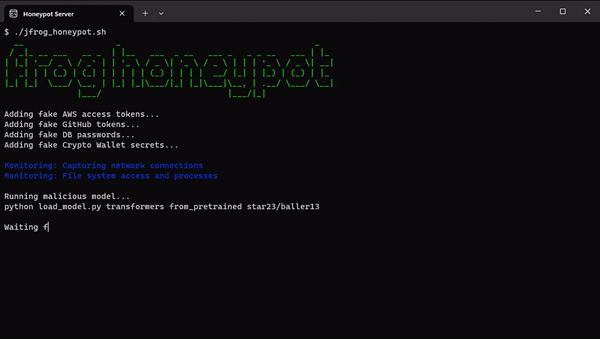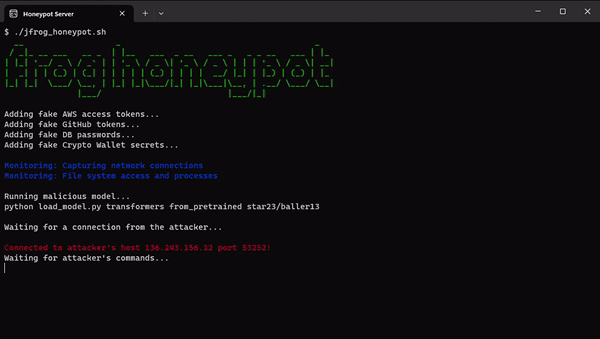
Das Aufkommen solcher Taktiken unterstreicht die Anfälligkeit von Supply-Chain-Angriffen, die auf bestimmte Zielgruppen wie KI/ML-Ingenieure und Pipeline-Maschinen zugeschnitten werden können. Darüber hinaus verdeutlicht eine aktuelle Schwachstelle in Transformern, CVE-2023-6730 , das Risiko transitiver Angriffe , die durch das Herunterladen scheinbar harmloser Modelle erleichtert werden und letztendlich zur Ausführung von Schadcode eines transitiven Modells führen. Diese Vorfälle erinnern eindringlich an die anhaltenden Bedrohungen, denen Hugging Face-Repositories und andere beliebte Repositories wie Kaggle ausgesetzt sind und die möglicherweise die Privatsphäre und Sicherheit von Organisationen gefährden könnten, die diese Ressourcen nutzen, und darüber hinaus eine Herausforderung für KI/ML-Ingenieure darstellen.

