Kommentare zu folgendem Beitrag: DuckAssist: DuckDuckGo integriert KI-Suche
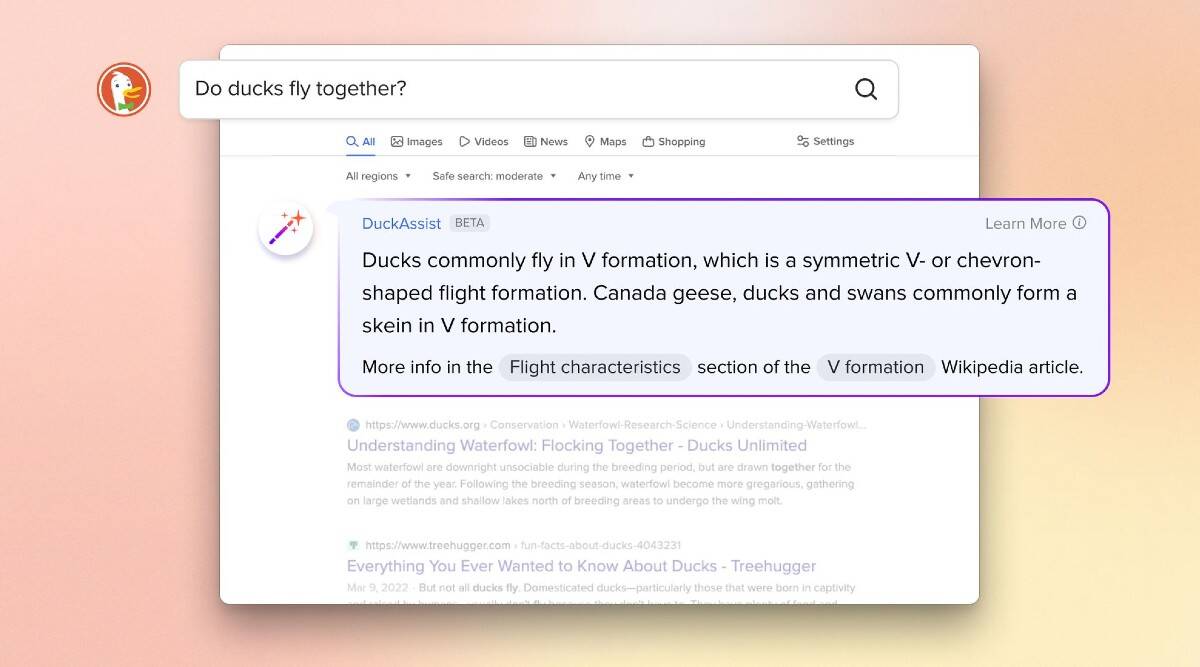
Als Konkurrenz zu Microsofts Bing und Braves Summarizer fasst DuckAssist von DuckDuckGo Suchergebnisse mit Infos aus Wikipedia zusammen.
Als Konkurrenz zu Microsofts Bing und Braves Summarizer fasst DuckAssist von DuckDuckGo Suchergebnisse mit Infos aus Wikipedia zusammen.
Ob ich das gut finden soll? Ich weiß nicht …
Weiß auch nicht. OpenAI lizensiert ihre KI-Modelle für Geld weiter. Es muss neu trainiert werden und das aus Daten ausschließlich von Wikipedia, und das kostet sicher. Vor allem ist GPT komplexer als das gewöhnliche Deep Learning.
Woher DuckDuckGo das Geld nimmt? Wohl aus den Werbeeinnahmen.
Wikipedia aber einzige Datenquelle find ich etwas merkwürdig, denn vieles ist fragwürdig und nicht 100% richtig, oder aber auch manchmal sehr veraltet
Wir haben GPT-4 entwickelt, den neuesten Meilenstein in den Bemühungen von OpenAI, Deep Learning zu erweitern. GPT-4 ist ein großes multimodales Modell (das Bild- und Texteingaben akzeptiert, Textausgaben ausgibt), das zwar in vielen realen Szenarien weniger leistungsfähig als Menschen ist, aber bei verschiedenen beruflichen und akademischen Benchmarks eine Leistung auf menschlicher Ebene aufweist. Zum Beispiel besteht es eine simulierte Anwaltsprüfung mit einer Punktzahl von etwa den besten 10 % der Testteilnehmer; Im Gegensatz dazu lag der Wert von GPT-3.5 bei den unteren 10 %. Wir haben 6 Monate damit verbracht, GPT-4 iterativ anzupassen , indem wir Lehren aus unserem gegnerischen Testprogramm sowie aus ChatGPT gezogen haben, was zu unseren besten Ergebnissen aller Zeiten (wenn auch weit davon entfernt, perfekt) in Bezug auf Sachlichkeit, Steuerbarkeit und Weigerung, die Leitplanken zu verlassen, geführt hat.
In den letzten zwei Jahren haben wir unseren gesamten Deep-Learning-Stack neu aufgebaut und gemeinsam mit Azure einen Supercomputer von Grund auf für unsere Workload entwickelt. Vor einem Jahr haben wir GPT-3.5 als ersten „Testlauf“ des Systems trainiert. Wir haben einige Fehler gefunden und behoben und unsere theoretischen Grundlagen verbessert. Infolgedessen war unser GPT-4-Trainingslauf (zumindest für uns!) beispiellos stabil und wurde zu unserem ersten großen Modell, dessen Trainingsleistung wir im Voraus genau vorhersagen konnten. Während wir uns weiterhin auf eine zuverlässige Skalierung konzentrieren, wollen wir unsere Methodik verfeinern, um uns dabei zu helfen, zukünftige Fähigkeiten immer weit im Voraus vorherzusagen und vorzubereiten – etwas, das wir als kritisch für die Sicherheit ansehen.
Wir veröffentlichen die Texteingabefunktion von GPT-4 über ChatGPT und die API (mit einer Warteliste ). Um die Bildeingabefunktion für eine breitere Verfügbarkeit vorzubereiten, arbeiten wir zunächst eng mit einem einzigen Partner zusammen. Wir bieten auch OpenAI Evals , unser Framework für die automatisierte Bewertung der Leistung von KI-Modellen, an, damit jeder Mängel in unseren Modellen melden kann, um weitere Verbesserungen anzuleiten.
In einem lockeren Gespräch kann der Unterschied zwischen GPT-3.5 und GPT-4 subtil sein. Der Unterschied zeigt sich, wenn die Komplexität der Aufgabe einen ausreichenden Schwellenwert erreicht – GPT-4 ist zuverlässiger, kreativer und in der Lage, viel nuanciertere Anweisungen zu verarbeiten als GPT-3.5.
Um den Unterschied zwischen den beiden Modellen zu verstehen, haben wir eine Vielzahl von Benchmarks getestet, einschließlich der Simulation von Prüfungen, die ursprünglich für Menschen entwickelt wurden. Wir sind vorgegangen, indem wir die neuesten öffentlich verfügbaren Tests verwendet haben (im Fall der Olympiaden und AP-Fragen mit kostenloser Antwort) oder indem wir die Ausgaben 2022–2023 der Übungsprüfungen gekauft haben. Wir haben kein spezielles Training für diese Prüfungen durchgeführt. Eine Minderheit der Probleme in den Prüfungen wurde vom Modell während des Trainings gesehen, aber wir glauben, dass die Ergebnisse repräsentativ sind!
Wir haben GPT-4 auch intern verwendet, mit großen Auswirkungen auf Funktionen wie Support, Verkauf, Inhaltsmoderation und Programmierung. Wir verwenden es auch, um Menschen bei der Bewertung von KI-Ergebnissen zu unterstützen und damit die zweite Phase unserer Ausrichtungsstrategie zu starten .
GPT-4 kann eine Eingabeaufforderung aus Text und Bildern akzeptieren, die es dem Benutzer – parallel zur Nur-Text-Einstellung – ermöglicht, jede visuelle oder sprachliche Aufgabe anzugeben. Insbesondere erzeugt es Textausgaben (natürliche Sprache, Code usw.) bei gegebenen Eingaben, die aus eingestreutem Text und Bildern bestehen. In einer Reihe von Bereichen – einschließlich Dokumenten mit Text und Fotos, Diagrammen oder Screenshots – weist GPT-4 ähnliche Fähigkeiten auf wie bei reinen Texteingaben. Darüber hinaus kann es mit Testzeittechniken erweitert werden, die für Nur-Text-Sprachmodelle entwickelt wurden, einschließlich der Eingabeaufforderung mit wenigen Schüssen und der Gedankenkette . Bildeingaben sind noch eine Forschungsvorschau und nicht öffentlich verfügbar.
Wir haben an jedem Aspekt des Plans gearbeitet, der in unserem Beitrag zur Definition des Verhaltens von KIs skizziert wurde , einschließlich der Steuerbarkeit. Anstelle der klassischen ChatGPT-Persönlichkeit mit fester Ausführlichkeit, Tonalität und Stil können Entwickler (und bald ChatGPT-Benutzer) jetzt den Stil und die Aufgabe ihrer KI vorschreiben, indem sie diese Anweisungen in der „System“-Nachricht beschreiben. Systemnachrichten ermöglichen es API-Benutzern, das Benutzererlebnis in Grenzen erheblich anzupassen . Wir werden hier weiter Verbesserungen vornehmen (und wissen insbesondere, dass Systemnachrichten der einfachste Weg sind, das aktuelle Modell zu „jailbreaken“, dh die Einhaltung der Grenzen ist nicht perfekt), aber wir ermutigen Sie, es auszuprobieren und uns mitzuteilen, was Sie denken.
Trotz seiner Fähigkeiten hat GPT-4 ähnliche Einschränkungen wie frühere GPT-Modelle. Am wichtigsten ist, dass es immer noch nicht vollständig zuverlässig ist (es „halluziniert“ Fakten und macht Denkfehler). Bei der Verwendung von Sprachmodellausgaben ist große Sorgfalt geboten, insbesondere in Kontexten mit hohem Einsatz.
Obwohl GPT-4 immer noch ein echtes Problem darstellt, reduziert es Halluzinationen im Vergleich zu früheren Modellen (die sich selbst mit jeder Iteration verbessert haben) erheblich. GPT-4 schneidet bei unseren internen kontradiktorischen Faktizitätsbewertungen um 40 % besser ab als unser neuestes GPT-3.5.
Das Basismodell GPT-4 ist bei dieser Aufgabe nur geringfügig besser als GPT-3.5; Nach dem RLHF -Nachtraining (unter Anwendung des gleichen Prozesses, den wir mit GPT-3.5 verwendet haben ) gibt es jedoch eine große Lücke. Betrachtet man unten einige Beispiele, widersetzt sich GPT-4 der Auswahl gängiger Redewendungen (man kann einem alten Hund keine neuen Tricks beibringen), kann jedoch immer noch subtile Details übersehen (Elvis Presley war nicht der Sohn eines Schauspielers).
Das Modell kann in seinen Ergebnissen verschiedene Verzerrungen aufweisen – wir haben diesbezüglich Fortschritte gemacht, aber es gibt noch mehr zu tun. Gemäß unserem letzten Blog-Beitrag wollen wir, dass KI-Systeme, die wir bauen, ein vernünftiges Standardverhalten haben, das eine breite Palette von Benutzerwerten widerspiegelt, dass diese Systeme innerhalb weiter Grenzen angepasst werden können, und dass wir öffentliche Eingaben dazu erhalten, wo diese Grenzen liegen sollten.
GPT-4 ist im Allgemeinen nicht über Ereignisse informiert, die nach der Unterbrechung der überwiegenden Mehrheit seiner Daten (September 2021) aufgetreten sind, und lernt nicht aus seinen Erfahrungen. Es kann manchmal einfache Denkfehler machen, die nicht mit der Kompetenz in so vielen Bereichen übereinstimmen, oder zu leichtgläubig sein, wenn es offensichtliche falsche Aussagen von einem Benutzer akzeptiert. Und manchmal kann es bei schwierigen Problemen genauso scheitern wie Menschen, beispielsweise beim Einfügen von Sicherheitslücken in den von ihm produzierten Code.
GPT-4 kann mit seinen Vorhersagen auch sicher falsch liegen und sich nicht darum kümmern, die Arbeit zu überprüfen, wenn es wahrscheinlich einen Fehler macht. Interessanterweise ist das vortrainierte Basismodell hochgradig kalibriert (sein vorhergesagtes Vertrauen in eine Antwort entspricht im Allgemeinen der Wahrscheinlichkeit, dass sie richtig ist). Durch unseren aktuellen Post-Training-Prozess wird die Kalibrierung jedoch reduziert.
Wir haben GPT-4 wiederholt, um es von Beginn des Trainings an sicherer und abgestimmter zu machen, mit Bemühungen wie der Auswahl und Filterung der Vortrainingsdaten, Bewertungen und Expertenengagement, Verbesserungen der Modellsicherheit sowie Überwachung und Durchsetzung.
GPT-4 birgt ähnliche Risiken wie frühere Modelle, z. B. das Generieren schädlicher Ratschläge, fehlerhafter Codes oder ungenauer Informationen. Die zusätzlichen Fähigkeiten von GPT-4 führen jedoch zu neuen Risikooberflächen. Um das Ausmaß dieser Risiken zu verstehen, haben wir über 50 Experten aus Bereichen wie KI-Ausrichtungsrisiken, Cybersicherheit, Biorisiko, Vertrauen und Sicherheit sowie internationale Sicherheit beauftragt, das Modell kontradiktorisch zu testen. Ihre Erkenntnisse ermöglichten es uns insbesondere, das Verhalten von Modellen in Bereichen mit hohem Risiko zu testen, für deren Bewertung Fachwissen erforderlich ist. Feedback und Daten dieser Experten flossen in unsere Abschwächungen und Verbesserungen für das Modell ein; Beispielsweise haben wir zusätzliche Daten gesammelt, um die Fähigkeit von GPT-4 zu verbessern, Anfragen zur Synthese gefährlicher Chemikalien abzulehnen.
GPT-4 enthält ein zusätzliches Sicherheitsbelohnungssignal während des RLHF-Trainings, um schädliche Ausgaben (wie in unseren Nutzungsrichtlinien definiert ) zu reduzieren, indem das Modell trainiert wird, Anfragen nach solchen Inhalten abzulehnen. Die Belohnung wird von einem GPT-4-Zero-Shot-Klassifikator bereitgestellt, der Sicherheitsgrenzen und den Abschlussstil bei sicherheitsbezogenen Eingabeaufforderungen beurteilt. Um zu verhindern, dass das Modell gültige Anfragen ablehnt, sammeln wir einen vielfältigen Datensatz aus verschiedenen Quellen (z. B. gekennzeichnete Produktionsdaten, menschliches Red-Teaming, vom Modell generierte Eingabeaufforderungen) und wenden das Sicherheitsbelohnungssignal (mit einem positiven oder negativen Wert) auf beide an erlaubte und nicht erlaubte Kategorien.
Unsere Schadensbegrenzungen haben viele der Sicherheitseigenschaften von GPT-4 im Vergleich zu GPT-3.5 erheblich verbessert. Wir haben die Tendenz des Modells, auf Anfragen nach unzulässigen Inhalten zu reagieren, im Vergleich zu GPT-3.5 um 82 % verringert, und GPT-4 reagiert gemäß unseren Richtlinien um 29 % häufiger auf sensible Anfragen (z. B. medizinische Beratung und Selbstverletzung).
Insgesamt erhöhen unsere Interventionen auf Modellebene die Schwierigkeit, schlechtes Verhalten hervorzurufen, aber dies ist immer noch möglich. Darüber hinaus gibt es noch „Jailbreaks“, um Inhalte zu generieren, die gegen unsere Nutzungsrichtlinien verstoßen . Da das „Risiko pro Token“ von KI-Systemen zunimmt, wird es entscheidend, bei diesen Eingriffen ein extrem hohes Maß an Zuverlässigkeit zu erreichen; Im Moment ist es wichtig, diese Einschränkungen durch Sicherheitstechniken zur Bereitstellungszeit wie die Überwachung auf Missbrauch zu ergänzen.
GPT-4 und Nachfolgemodelle haben das Potenzial, die Gesellschaft sowohl auf positive als auch auf schädliche Weise erheblich zu beeinflussen. Wir arbeiten mit externen Forschern zusammen, um unser Verständnis und die Bewertung potenzieller Auswirkungen zu verbessern und um Bewertungen für gefährliche Fähigkeiten zu erstellen, die in zukünftigen Systemen auftreten können. Wir werden bald mehr über unsere Gedanken zu den möglichen sozialen und wirtschaftlichen Auswirkungen von GPT-4 und anderen KI-Systemen berichten.
Wie frühere GPT-Modelle wurde das GPT-4-Basismodell darauf trainiert, das nächste Wort in einem Dokument vorherzusagen, und wurde mit öffentlich verfügbaren Daten (z. B. Internetdaten) sowie von uns lizenzierten Daten trainiert. Die Daten sind ein webbasierter Datenkorpus, der korrekte und falsche Lösungen für mathematische Probleme, schwache und starke Argumentation, widersprüchliche und konsistente Aussagen enthält und eine große Vielfalt von Ideologien und Ideen repräsentiert.
Wenn also eine Frage gestellt wird, kann das Basismodell auf eine Vielzahl von Arten antworten, die möglicherweise weit von der Absicht eines Benutzers entfernt sind. Um es mit der Absicht des Benutzers innerhalb der Leitplanken in Einklang zu bringen, optimieren wir das Verhalten des Modells mithilfe von Verstärkungslernen mit menschlichem Feedback ( RLHF ).
Beachten Sie, dass die Fähigkeiten des Modells hauptsächlich aus dem Vortrainingsprozess zu stammen scheinen – RLHF verbessert die Prüfungsleistung nicht (ohne aktive Anstrengung verschlechtert es sie tatsächlich). Aber die Steuerung des Modells kommt aus dem Post-Training-Prozess – das Basismodell erfordert eine schnelle Entwicklung, um überhaupt zu wissen, dass es die Fragen beantworten sollte.
Ein großer Schwerpunkt des GPT-4-Projekts war der Aufbau eines Deep-Learning-Stacks, der vorhersagbar skaliert. Der Hauptgrund ist, dass es bei sehr großen Trainingsläufen wie GPT-4 nicht möglich ist, umfangreiches modellspezifisches Tuning durchzuführen. Wir haben eine Infrastruktur und Optimierung entwickelt, die über mehrere Skalen hinweg ein sehr vorhersehbares Verhalten aufweisen. Um diese Skalierbarkeit zu überprüfen, haben wir den endgültigen Verlust von GPT-4 auf unserer internen Codebasis (nicht Teil des Trainingssatzes) im Voraus genau vorhergesagt, indem wir aus Modellen extrapoliert haben, die mit derselben Methodik, aber mit 10.000-mal weniger Rechenleistung trainiert wurden.
Jetzt, da wir die Metrik, die wir während des Trainings optimieren (Verlust), genau vorhersagen können, beginnen wir mit der Entwicklung einer Methodik zur Vorhersage besser interpretierbarer Metriken. Beispielsweise haben wir erfolgreich die Bestehensquote für eine Teilmenge des HumanEval- Datensatzes vorhergesagt, indem wir aus Modellen mit 1.000-mal weniger Rechenleistung extrapoliert haben.
Einige Fähigkeiten sind immer noch schwer vorherzusagen. Beispielsweise war der Inverse Scaling Prize ein Wettbewerb, bei dem es darum ging, eine Metrik zu finden, die mit zunehmender Modellberechnung schlechter wird, und Vernachlässigung im Nachhinein war einer der Gewinner. Genau wie bei einem anderen aktuellen Ergebnis kehrt GPT-4 den Trend um.
Wir glauben, dass die genaue Vorhersage zukünftiger maschineller Lernfähigkeiten ein wichtiger Teil der Sicherheit ist, der im Verhältnis zu seinen potenziellen Auswirkungen nicht annähernd genug Aufmerksamkeit erhält (obwohl wir durch Bemühungen mehrerer Institutionen ermutigt wurden). Wir intensivieren unsere Bemühungen zur Entwicklung von Methoden, die der Gesellschaft bessere Orientierungshilfen dafür bieten, was von zukünftigen Systemen zu erwarten ist, und wir hoffen, dass dies zu einem gemeinsamen Ziel in diesem Bereich wird.
Wir bieten OpenAI Evals , unser Software-Framework zum Erstellen und Ausführen von Benchmarks für die Bewertung von Modellen wie GPT-4, und prüfen gleichzeitig ihre Leistung Stichprobe für Stichprobe. Wir verwenden Evals, um die Entwicklung unserer Modelle zu leiten (sowohl zur Identifizierung von Mängeln als auch zur Verhinderung von Regressionen), und unsere Benutzer können es anwenden, um die Leistung über Modellversionen hinweg (die jetzt regelmäßig herauskommen) und die Weiterentwicklung von Produktintegrationen zu verfolgen. Beispielsweise hat Stripe Evals verwendet, um seine menschlichen Bewertungen zu ergänzen und die Genauigkeit seines GPT-gestützten Dokumentationstools zu messen.
Da der gesamte Code Open Source ist, unterstützt Evals das Schreiben neuer Klassen zum Implementieren benutzerdefinierter Auswertungslogik . Nach unserer eigenen Erfahrung folgen jedoch viele Benchmarks einer von wenigen „Vorlagen“, daher haben wir auch die Vorlagen aufgenommen , die intern am nützlichsten waren (einschließlich einer Vorlage für „Modell-bewertete Bewertungen“ – wir haben festgestellt, dass GPT- 4 ist überraschenderweise in der Lage, seine eigene Arbeit zu überprüfen). Im Allgemeinen besteht die effektivste Methode zum Erstellen einer neuen Bewertung darin, eine dieser Vorlagen zusammen mit der Bereitstellung von Daten zu instanziieren. Wir sind gespannt, was andere mit diesen Vorlagen und mit Evaluierungen im Allgemeinen erstellen können.
Wir hoffen, dass Evals zu einem Mittel wird, um Benchmarks zu teilen und zu sammeln, die eine möglichst breite Palette von Fehlermodi und schwierigen Aufgaben darstellen. Als Beispiel haben wir eine Logikrätsel- Evaluierung erstellt, die zehn Eingabeaufforderungen enthält, bei denen GPT-4 fehlschlägt. Evals ist auch mit der Implementierung bestehender Benchmarks kompatibel; Wir haben mehrere Notebooks beigefügt , die akademische Benchmarks und einige Variationen der Integration (kleiner Teilmengen von) CoQA als Beispiel implementieren.
Wir laden alle ein, Evals zu verwenden, um unsere Modelle zu testen und die interessantesten Beispiele einzureichen. Wir glauben, dass Evals ein integraler Bestandteil des Prozesses für die Verwendung und den Aufbau unserer Modelle sein werden, und wir freuen uns über direkte Beiträge, Fragen und Feedback.
ChatGPT Plus
Abonnenten von ChatGPT Plus erhalten GPT-4-Zugriff auf chat.openai.com mit einer Nutzungsobergrenze. Wir werden die genaue Nutzungsobergrenze je nach Bedarf und Systemleistung in der Praxis anpassen, gehen jedoch davon aus, dass die Kapazität stark eingeschränkt sein wird (obwohl wir in den kommenden Monaten skalieren und optimieren werden).
Abhängig von den Verkehrsmustern, die wir sehen, führen wir möglicherweise eine neue Abonnementstufe für die GPT-4-Nutzung mit höherem Volumen ein. Wir hoffen auch, irgendwann eine Anzahl kostenloser GPT-4-Abfragen anbieten zu können, damit auch diejenigen ohne Abonnement es ausprobieren können.
Um Zugriff auf die GPT-4-API zu erhalten (die dieselbe ChatCompletions-API wie gpt-3.5-turbo verwendet), melden Sie sich bitte für unsere Warteliste an . Wir werden heute beginnen, einige Entwickler einzuladen, und schrittweise skalieren, um die Kapazität mit der Nachfrage in Einklang zu bringen. Wenn Sie ein Forscher sind, der die gesellschaftlichen Auswirkungen von KI oder Fragen der KI-Ausrichtung untersucht, können Sie auch einen subventionierten Zugang über unser Researcher Access Program beantragen .
Sobald Sie Zugriff haben, können Sie Nur-Text-Anfragen an das gpt-4-Modell stellen (Bildeingaben befinden sich noch in begrenztem Alpha), das wir automatisch auf unser empfohlenes stabiles Modell aktualisieren, wenn wir im Laufe der Zeit neue Versionen erstellen (Sie können die aktuelle Version durch Aufruf von gpt-4-0314, die wir bis zum 14. Juni unterstützen). Der Preis beträgt 0,03 USD pro 1.000 Aufforderungstoken und 0,06 USD pro 1.000 Abschlusstoken. Standardratenlimits sind 40.000 Token pro Minute und 200 Anfragen pro Minute.
GPT-4 hat eine Kontextlänge von 8.192 Token. Wir bieten auch eingeschränkten Zugriff auf unsere 32.768-Kontext-Version (etwa 50 Seiten Text), gpt-4-32k, die im Laufe der Zeit ebenfalls automatisch aktualisiert wird (aktuelle Version gpt-4-32k-0314, ebenfalls bis zum 14 ). Der Preis beträgt 0,06 USD pro 1.000 Aufforderungstoken und 0,12 USD pro 1.000 Abschlusstoken. Wir verbessern immer noch die Modellqualität für lange Kontexte und würden uns über Feedback zur Leistung für Ihren Anwendungsfall freuen. Wir bearbeiten Anfragen für die 8K- und 32K-Engines je nach Kapazität zu unterschiedlichen Raten, sodass Sie möglicherweise zu unterschiedlichen Zeiten darauf zugreifen können.
Wir freuen uns darauf, dass GPT-4 ein wertvolles Werkzeug wird, um das Leben der Menschen zu verbessern, indem es viele Anwendungen unterstützt. Es gibt noch viel zu tun, und wir freuen uns darauf, dieses Modell durch die gemeinsamen Anstrengungen der Community zu verbessern, die auf dem Modell aufbauen, es erforschen und dazu beitragen.