
Kommentare zu folgendem Beitrag: Chatkontrolle: EU-Kommission für Durchsuchung aller Endgeräte
Im Rahmen der geplanten Chatkontrolle im Kampf gegen Kindesmissbrauch soll es künftig erlaubt sein, die Medien der Endgeräte zu überprüfen.
Kommentare zu folgendem Beitrag: Chatkontrolle: EU-Kommission für Durchsuchung aller Endgeräte
Im Rahmen der geplanten Chatkontrolle im Kampf gegen Kindesmissbrauch soll es künftig erlaubt sein, die Medien der Endgeräte zu überprüfen.
Zudem besteht auch die Gefahr, dass wenn erst einmal der Zugang zu irgendwelchen Endgeräten verfügbar sein sollte, Behörden früher oder später auch bei Straftaten mit einer geringeren kriminellen Energie den Inhalt unserer Geräte überprüfen wollen.
Noch viel wichtiger wäre wohl:
Wer oder was garantiert dann, dass es nicht zu einer ansatzlosen Überwachung, quasi 24/7, bei allen ans Internet angebundenen Geräten kommt??
Bei solch einer Kontrolle wäre dann wohl das Chat-Programm der Bundestrojaner, den man sich als User „freiwillig“ auf sein Endgerät installiert…!
Datenschutz und Verschlüsselung sei gegenüber dem Schutz der Opfer nachrangig zu behandeln, sagte die Politikerin.
Hat die Schwedin auch mal drüber nachgedacht, dass auch ein Opfer gerne seine eigenen Daten geschützt haben möchte??
Im Übrigen kann man ein Opfer nicht mehr schützen, da die eigentliche Tat ja schon begangen wurde! Ansonsten wäre diese Person ja kein Opfer!
Die 22 Millionen Meldungen, die freiwillig eingegangen sind, würden nämlich nur einen Bruchteil der tatsächlichen Straftaten darstellen.
Könnte wohl auch daran liegen, dass die restlichen Straftaten auf ganz anderen Wegen zustande gekommen sind und so rein gar nichts mit Messengern zu tun hat…!
Mich würde der technische Aspekt des css interesieren, wie das funktioniert. Kann man das nicht hard- oder software seitig verhindern? Was wenn man ein custom Rom ohne google Dienste verwendet? Es kann doch nicht möglich sein das der Staat ein Endgerät bemerkt oder unbemerkt online in realtime durchsuchen kann, ohne dass man es verhindern kann?
Zum technischen Ablauf des CSS habe ich das hier noch gefunden:
Viele Anbieter von Online-Diensten, die es Nutzern erlauben, beliebige Inhalte an andere Nutzer zu senden führen bereits regelmäßige Scans durch, um anstößiges Material zu erkennen und in einigen
Fällen an die Behörden melden. Zu den gezielten Inhalten können Spam, Hassreden,
Tierquälerei und, bei einigen Anbietern, Nacktheit. Lokale Gesetze können eine Meldung
oder Entfernung vorschreiben. Frankreich und Deutschland zum Beispiel verlangen seit Jahren die Entfernung von Nazi-Material,
und die EU hat angeordnet, dass dies in allen Mitgliedstaaten generell auf terroristisches Material ausgeweitet wird.
In den USA sind die Anbieter verpflichtet, Inhalte, die als
Inhalte, die als CSAM gekennzeichnet sind, an eine Clearingstelle zu melden, die vom National Center for Missing and Exploited Children (NCMEC) betrieben wird, während im Vereinigten Königreich eine ähnliche Funktion von der Internet Watch Foundation (IWF).
In der Vergangenheit wurden Mechanismen zum Scannen von Inhalten auf Servern der Provider implementiert. Seit Mitte der 2000er Jahre hat das Scannen dazu beigetragen, die Forschung im Bereich der Technologien des maschinellen Lernens voranzutreiben, die ab 2003 erstmals in Spam-Filtern eingesetzt wurden. Allerdings Scannen ist jedoch teuer, insbesondere bei komplexen Inhalten wie Videos. Große maschinelle Lernmodelle, die auf mehreren Servern laufen, werden in der Regel durch Tausende von menschlichen Moderatoren ergänzt, die verdächtige Inhalte prüfen und klassifizieren. Diese Menschen lösen nicht nur schwierige Grenzfälle, sondern helfen auch, die maschinellen Lernmodelle zu trainieren und ermöglichen es ihnen, sich an neue Arten von Missbrauch anzupassen.
Ein Anreiz für Unternehmen, eine Ende-zu-Ende-Verschlüsselung einzuführen, könnten die Kosten für die
Moderation sein. Allein Facebook hat 15.000 menschliche Moderatoren, und Kritiker haben vorgeschlagen
Kritiker haben vorgeschlagen, ihre Zahl zu verdoppeln.13 Die Belastung durch diesen Prozess wird durch
Ende-zu-Ende-Verschlüsselung erheblich reduziert, da die Nachrichtenserver keinen Zugriff mehr auf die Inhalte haben.
Ein Teil der Moderation erfolgt weiterhin auf der Grundlage von Nutzerbeschwerden und der Analyse von Metadaten.
Einige Regierungen haben jedoch mit dem Druck reagiert, das Scannen
auf den Geräten der Benutzer.
In diesem Abschnitt fassen wir die aktuellen technischen Mittel zur Implementierung des Scannens zusammen,
und untersuchen den Unterschied zwischen dem Einsatz solcher Methoden auf dem Server oder auf dem
Client.
Methoden zum Scannen von Inhalten:
Derzeit werden zwei verschiedene Technologien für das Scannen von Bildern verwendet: Perceptual Hashing und maschinelles Lernen.
Wahrnehmungsbasiertes Hashing. Hashes sind spezielle Algorithmen, die eine große Eingabedatei verdauen und einen kurzen eindeutigen „Fingerabdruck“ oder Hash zu erzeugen. Viele Scansysteme nutzen wahrnehmungsbasierte Hash-Funktionen, die sich aufgrund mehrerer Merkmale
ideal für die Identifizierung von Bildern sind. Vor allem sind sie unempfindlich gegenüber kleinen Änderungen des Bildinhalts, wie z. B. eine Neucodierung oder eine Änderung der Bildgröße. Einige
Funktionen sind sogar unempfindlich gegenüber Bildbeschneidung und -drehung.
Wahrnehmungshashes können für Benutzerinhalte berechnet und dann mit einer
Datenbank mit gezielten Medien-Fingerprints verglichen werden, um Dateien zu erkennen, die identisch
oder sehr ähnlich zu bekannten Bildern sind. Der Vorteil dieses Ansatzes ist ein zweifacher: (1)
der Vergleich kurzer Fingerabdrücke ist effizienter als der Vergleich ganzer Bilder, und (2)
Durch die Speicherung einer Liste von gezielten Fingerabdrücken müssen die Anbieter die Bilder nicht speichern und besitzen.
Der Besitz von solchem Material ist in vielen Ländern strafbar; Anbieter, die darauf stoßen, sind verpflichtet, es sofort zu melden und zu vernichten. Nationale Missbrauchsorganisationen wie NCMEC in den USA und IWF im Vereinigten Königreich erhalten diese Meldungen und sind rechtlich befugt, solches Material aufzubewahren und zu kuratieren.
Die Dienstanbieter verwenden daher eine Liste mit Hashes von Bildern, die von diesen Organisationen zusammengestellt wurden. Beispiele für Wahrnehmungs-Hash-Funktionen sind phash, die PhotoDNA von Microsoft , die PDQ-Hash-Funktion von Facebook und die NeuralHash-Funktion von Apple
Maschinelles Lernen. Der alternative Ansatz zur Bildklassifizierung verwendet Techniken des maschinellen Lernens, um gezielte Inhalte zu identifizieren. Dies ist derzeit die beste Methode zur
Filterung von Videos und in der Regel auch die beste Methode zur Filterung von Text. Der Anbieter trainiert zunächst ein Machine-Learning-Modell mit Bildsätzen, die sowohl harmlose als auch zielgerichtete Inhalte enthalten. Dieses
Modell wird dann verwendet, um von Nutzern hochgeladene Bilder zu scannen. Anders als beim Wahrnehmungs-Hashing,
das nur Fotos erkennt, die bekannten Zielfotos ähnlich sind, können maschinenlernende
Modelle völlig neue Bilder des Typs erkennen, für den sie trainiert wurden.
Ein bekanntes Beispiel ist der Gesichtsdetektor, der in iPhones verwendet wird, um Gesichter zu erkennen, auf die die Kamera fokussiert werden soll.
Obwohl diese beiden Scantechnologien unterschiedlich funktionieren, haben sie einige gemeinsame Eigenschaften. Beide erfordern für den Abgleich Zugriff auf unverschlüsselte Inhalte. Beide können
Beide können Dateien erkennen, die das System noch nicht gesehen hat, obwohl Perceptual Hashing darauf beschränkt ist, Dateien zu erkennen, die sich nur geringfügig von Bildern unterscheiden, die es bereits gesehen hat. Beide Methoden haben eine Falsch-Positiv-Rate ungleich Null. Beide Methoden stützen sich auf ein proprietäres Tool, das aus einem Korpus gezielter Inhalte entwickelt wurde, der von einem Dritten kontrolliert werden kann. Einige Scanning-Techniken verwenden auch proprietäre Algorithmen (z. B., Microsofts PhotoDNA ist nur im Rahmen einer Geheimhaltungsvereinbarung verfügbar).
Unabhängig von der zugrundeliegenden Technologie kann jede Methode als Blackbox behandelt werden
die ein unverschlüsseltes Bild eingibt und eine Aussage darüber trifft, ob es wahrscheinlich
gezieltes Material enthält.
Diese Gemeinsamkeiten führen dazu, dass Scans, die auf beiden Methoden basieren, sehr ähnliche
Sicherheitseigenschaften aufweisen. Beide Methoden können von sachkundigen Angreifern umgangen werden; und beide Methoden können auf ähnliche Weise unterwandert werden.
Arbeitsabläufe beim Scannen von Inhalten:
Wie im vorangegangenen Abschnitt erläutert, kann das Scannen verwendet werden, um festzustellen, ob der
Nutzer Inhalte auf einer Liste mit bekanntermaßen schlechten Inhalten hat (z. B. durch Perceptual Hashing, um festzustellen, ob
der Benutzer ein bekanntes CSAM-Bild hat) oder um Inhalte einer Zielklasse zu finden (z. B. durch
maschinelles Lernen). Wir beschreiben nun den Ablauf der Aktionen zur Durchführung des Scannens auf
dem Server bzw. auf dem Client.
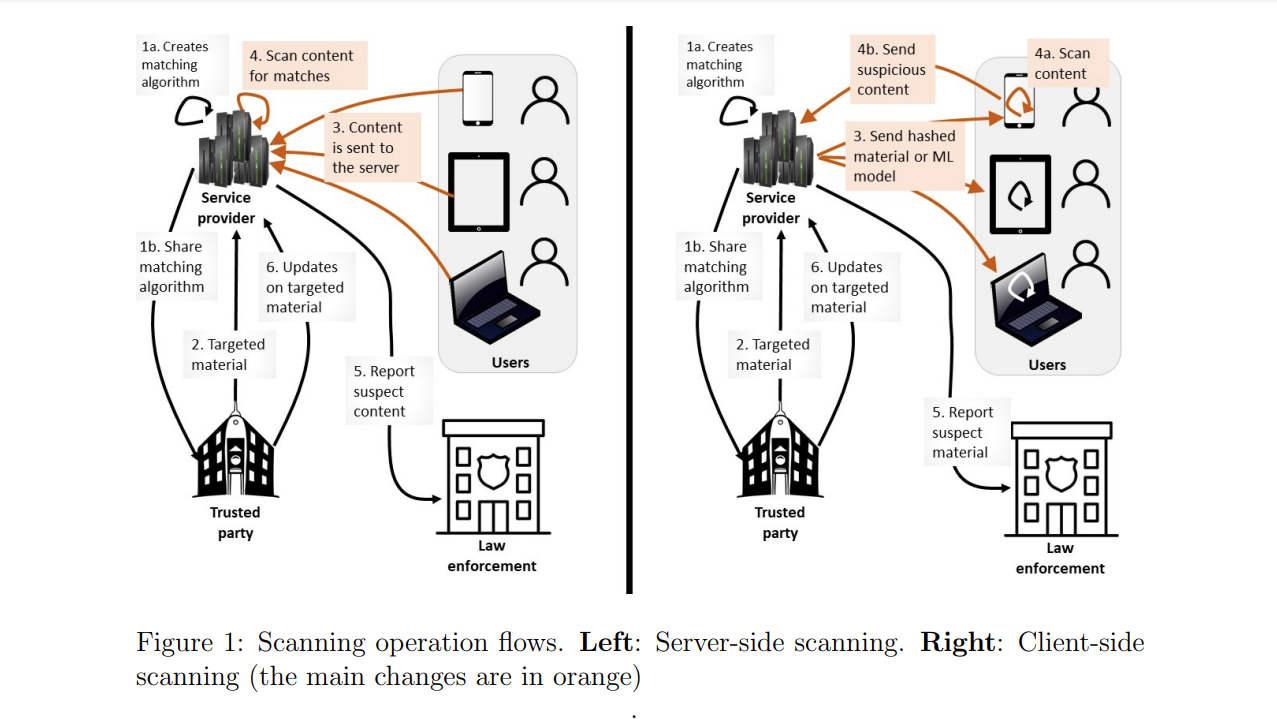
Scannen auf dem Server. Derzeit laufen die Scan-Prozesse der meisten Technologieunternehmen
auf ihren eigenen Servern. Hierfür gibt es zwei Gründe. Erstens verpflichten sich die Unternehmen, nur
nur bestimmte Arten von Material zu hosten oder zu übertragen, und die Kunden müssen dem zustimmen
wenn sie sich für den Dienst registrieren. Die Unternehmen durchsuchen dann die Kundendaten, um die
die Weitergabe von Material zu verhindern, das illegal ist oder gegen ihre Nutzungsbedingungen verstößt (z. B. im Fall von Facebook
Fall: Nacktheit). Zweitens ist es bequem: Die Kundendaten sind auf den Servern der Unternehmen leicht zugänglich
Servern, die über die nötige Rechenkapazität verfügen. Da sich die Technologie
sich die Technologie weiterentwickelt hat, senden sich die Menschen Bilder und andere Inhalte nicht immer direkt,
sondern senden Links zu in der Cloud gespeichertem Material. Dies ermöglicht es Technologieunternehmen
gemeinsame Bilder zu durchsuchen17 und bedeutet, dass die Technologieunternehmen in der Regel nicht
Material, das nur einem einzigen Konto oder einer einzigen Person vorbehalten ist.
Wir werden nun den operativen Ablauf betrachten, beginnend mit dem Fall der serverseitigen Scanning mit Perceptual Hashing:
In einigen CSS-Varianten kann das System anstelle der Strafverfolgungsbehörden auch andere Parteien benachrichtigen. Wenn beispielsweise in Schritt 4 zielgerichtete Inhalte gefunden werden, werden diese nicht
an den Server zu senden oder die Strafverfolgungsbehörden zu benachrichtigen (Schritt 5), kann das CSS-System eine
eine lokale Benachrichtigung auslösen, um den Nutzer an der Durchführung einer Aktion zu hindern oder ihn zu bitten, die
zu überdenken. Alternativ kann das CSS-System auch andere Personen benachrichtigen, z. B. die Eltern oder
Erziehungsberechtigten eines Kindes benachrichtigen, wenn das Gerät einem Minderjährigen gehört.22 Unsere Analyse in den folgenden
gilt unabhängig davon, wen das CSS-System benachrichtigt, wenn es eine Übereinstimmung findet.
CSS ist so konzipiert, dass es dem serverseitigen Scannen ähnelt und sich der Kontrolle des Benutzers entzieht,
und alles zu durchsuchen, ohne dass ein Durchsuchungsbefehl oder ein individueller Verdacht vorliegt. Dennoch
fehlen ihm einige der Vorteile des serverseitigen Scannens. Zumindest ein Teil des
Scanning-Algorithmus muss auf dem Client ausgeführt werden, was die Gefahr mit sich bringt, dass er zusammen mit den
zusammen mit den Targeting-Daten, wie einer Liste von Hashes oder einem ML-Modell, öffentlich gemacht werden.
Bei der Verwendung eines ML-Modells anstelle eines perzeptiven Hashes bestünde ein erhöhtes
ein erhöhtes Risiko, dass ein Angreifer einen Angriff zur Modellextraktion durchführt oder sogar einen Teil der
Wir werden dies später in Abschnitt 4.1 näher erläutern.
Bei CSS ist der Anbieter auch in Bezug auf Berechnungen und Daten eingeschränkt. Für
Man denke beispielsweise an die Forderung der EU, Textnachrichten zu scannen, um schwere Verbrechen zu erkennen,
einschließlich Grooming und Rekrutierung von Terroristen. Gegenwärtig verwendet Europol das Scannen von Schlüsselwörtern - Scannen mit einer Liste von etwa 5.000 Wörtern in mehreren Sprachen - darunter auch Slangbegriffe für Drogen und Schusswaffen. Würde eine solche Methode in großem Umfang auf den Geräten der Nutzer eingesetzt, würde sie vermutlich jeden melden, der mehr als eine bestimmte Anzahl dieser Wörter in seinen ihren Nachrichten haben. Dies würde zu vielen Fehlalarmen bei gesetzestreuen Jägern führen, Waffensammlern, Schriftstellern und dergleichen. CSS kann sich nicht auf die groß angelegten Clustering
von modernen Spam-Filtern verlassen; und die Bestimmung von Thema und Absicht in großen
Textkorpora sind schwierige Probleme.
Danke! Das ist ja ein richtiges WIKI ![]()
Ich finde es erschreckend wie von Microsoft und Google Cloud Usern der Content automatisiert überwacht wird. Wenigstens nützt (noch) Verschlüsselung dagegen.
„CSS ist so konzipiert, dass es dem serverseitigen Scannen ähnelt und sich der Kontrolle des Benutzers entzieht,
und alles zu durchsuchen, ohne dass ein Durchsuchungsbefehl oder ein individueller Verdacht vorliegt.“
Hier frage ich mich wie das css auf dem Endgerät gestartet wird. Das kann doch nur eine Funktion der jeweiligen App von Microsoft, Facebook, Instagram, TicToc usw sein? Also nur wenn die App installiert und ausgeführt wird.
Oder kann CSS auch über einen Trojaner, getarnt als irgendein App Update, Firmware Update ausgeführt werden. Eventuell sogar wenn man im Google / Microsoft Konto eingeloggt ist (Android), dass dann Google / Microsoft Code auf jedem Endgerät über die Google Suche, Youtube, gmail, Google Navigation usw ausführen kann.
Die Hashes sollen laut dem Text weitegehend resistent gegen Bildänderungen sein. Ob sie resistent gegen alle meta exif Daten sind, die man mit Tools von Bildern, und pdf Dateien entfernen kann? In dem Fall würde ein css ins Leere laufen.
Dann ist noch fraglich, ob css OS unabhängig funktioniert, zB auch bei Linux oder einem Ubuntu Phone.
Meiner Meinung nach ist das erst der Anfang und wird irgendwann auch für torrents, warez, Filme usw. angedacht.
Ich vermute mal, dass CSS in dem Sinne gar nicht gestartet werden muss, sondern das dies ähnlich funktioniert, wie ein „always-on“ Dienst im Windows, der auf eine Schnittstelle (z.B. Port) horcht / lauscht und bei Traffic direkt ohne Verzögerung aktiv ist! Um diesen „Scanner“ nun initial auf ein Gerät zu bringen, gibt es ja die verschiedensten Möglichkeiten - dies müsste allerdings dann genauso per Gesetz geregelt werden, wie die Überprüfungen selber!!
Ich habe mal hier den Bericht der hier erwähnten 14 Sicherheitsforscher übersetzt. In dieser CSS-Studie wird ja auch relativ detailliert auf die technischen Möglichkeiten eingegangen…siehe:
https://anonfiles.com/VdO4a3C0x9/2110.07450_pdf
Ich hab zwar länger suchen müssen, aber ich habe dann doch noch das Grundlagenpapier der EU-Kommission gefunden, auf welches sich diese EU-Kommissarin Ylva Johansson beruft:
https://anonfiles.com/38O8a1Cax8/SKM_C45820090717470-1_new_de_pdf
Dieses Dokument wurde von der Europäischen Kommission nicht angenommen oder
gebilligt und ist als Diskussionsgrundlage gedacht. Es darf ohne Genehmigung der
Dienststellen der Europäischen Kommission nicht weitergegeben werden.
Dort in diesem EU-Papier werden u.a. auf der internen Seite 10 u. 11 die Integrationsmöglichkeiten eines solchen Tools angerissen - aber keine Angst, denn es wird noch richtig interessant in den Folgeseiten, sogar teilweise richtig absurd !! ![]()
Wird wohl auch einer der Gründe sein, wieso diese Diskussionsgrundlage nicht in die Öffentlichkeit soll…

